深度强化学习从入门到大师:以Doom为例一文带你读懂深度Q学习(第三部分 - 上)
翻译 | 斯蒂芬•二狗子
校对 | 酱番梨 整理 | 菠萝妹
原文链接:
深度强化学习从入门到大师:以Doom为例一文带你读懂深度Q学习(第三部分)
本文是Tensorflow深度强化学习课程的一部分。点击这里查看教学大纲。
上一次,我们学习了Q-Learning:一种算法,它生成一个Q表,Agent用它来查找给定状态时采取的最佳动作。
但正如我们所看到的,状态空间是大型环境时,生成和更新Q表可能会失效。
本文是关于深度强化学习的一系列博客文章的第三部分。有关更多信息和更多资源,请查看 课程的教学大纲。
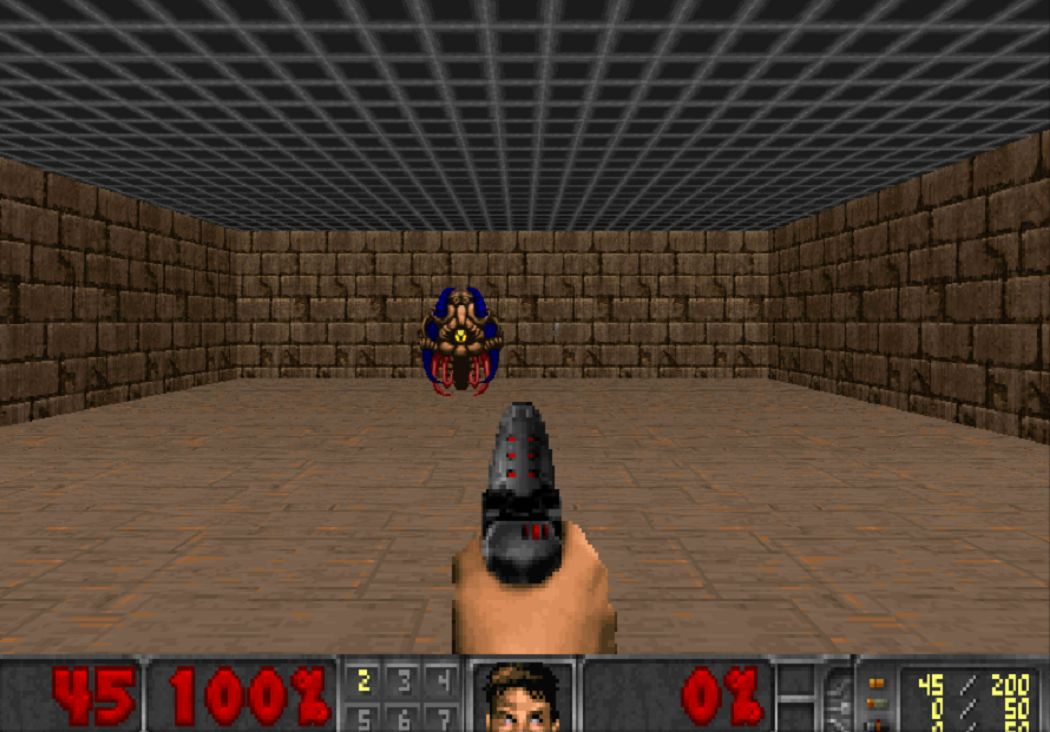
今天,我们将创建一个Deep Q神经网络。我们通过一个神经网络实现,而不是使用Q表,该神经网络获取智能体的状态并为该状态的每个动作计算Q值。
多亏了这个模型,我们将能够创建一个学习如何玩Doom的智能体 !
我们的DQN智能体
在本文中,您将学习:
什么是Deep Q-Learning(DQL)?
使用DQL的最佳策略是什么?
如何处理时间限制问题
为什么我们使用经验回放
DQL背后的数学是什么?
如何在Tensorflow中实现它
为Q-Learning添加“深度”
在 上一篇文章中,我们通过Q学习算法创建了一个扮演Frozen Lake的智能体。
我们实现了Q-learning函数来创建和更新Q表。根据到当前的状态,可以将此视为“作弊表”,以帮助我们找到行动的最大预期未来奖励。这是一个很好的策略 - 但是,这种方法不可扩展。
想象一下我们今天要做的事情。我们将创建一个学习玩Doom的智能体。
Doom是一个拥有巨大状态空间(数百万不同state)的大环境。为该环境创建和更新Q表的效率可想而知。
在这种情况下,最好的想法是创建一个神经网络 ,这个网络在给定状态的情况下 ,将近似每个动作的不同Q值。
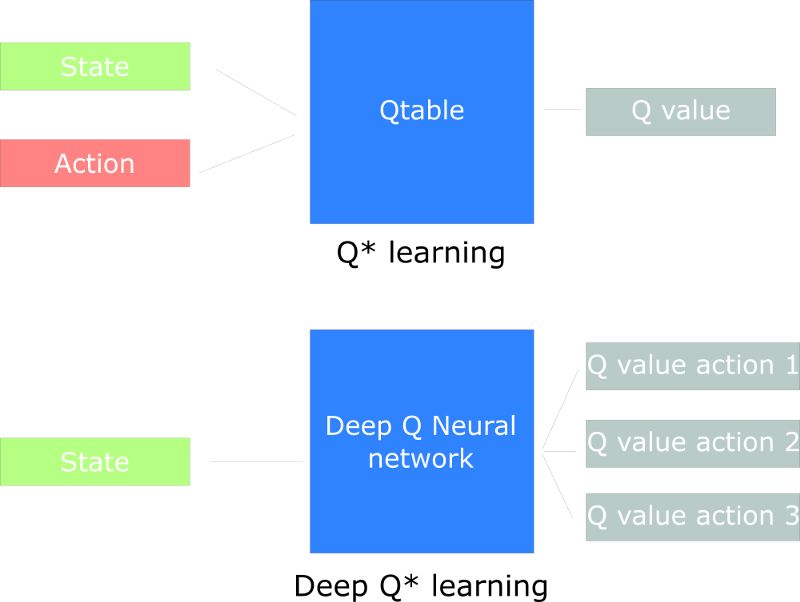
Deep Q-Learning是如何工作的?
深度Q学习的架构:
这看起来很复杂,但我会逐步解释这个架构。
我们的深度Q学习神经网络以四个图像帧的堆叠作为输入。它们通过其网络,并在给定状态下为每个可能的动作输出Q值向量。我们需要采用此向量的最大Q值来找到我们最好的行动。
一开始,智能体的表现非常糟糕。但随着时间的推移,它开始将 图像帧(状态)与最佳动作联系起来。
预处理部分
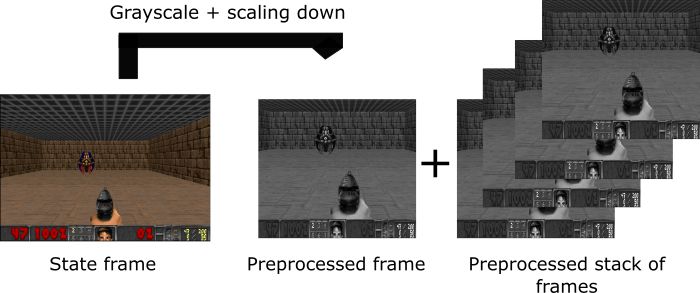
预处理是重要的一步。我们希望降低状态的复杂性,以减少培训所需的计算时间。
首先,我们可以对每个state进行灰度化。颜色不会添加重要信息(在我们的例子中,我们只需要找到敌人并杀死他,我们不需要颜色来找到他)。这是一个重要的节省,因为我们将三种颜色通道(RGB)减少到1(灰度)。
然后,我们裁剪图像。在我们的例子中,看到屋顶并不是真的有用。
然后我们减小每帧图的大小,并将四个子帧叠加在一起。
时间限制的问题
Arthur Juliani 在他的文章中对这个主题给出了一个很棒的解释 。他有一个聪明的主意:使用 LSTM神经网络 来处理。
但是,我认为初学者使用堆叠图像会更好。
您可能问的第一个问题是我们为什么要将图像帧叠加在一起?
我们将帧堆叠在一起,因为它有助于我们处理时间限制(temporal limitation)的问题。
让我们举一个例子,在 Pong 游戏中。当你看到这个图片时:

你能告诉我球在哪里吗?
不能,因为一帧图片不足以产生运动感!
但是,如果我再添加三个帧怎么办?在这里你可以看到球向右移动。

这对我们的Doom智能体来说是一样的。如果我们一次只给他一帧图片,它就不知道该如何行动了。如果不能确定物体移动的位置和速度,它怎么能做出正确的决定呢?
使用卷积网络
帧由三个卷积层处理。这些图层允许您利用图像中的空间关系。但是,因为帧堆叠在一起,您可以利用这些帧的一些空间属性。
如果你不熟悉卷积,请仔细阅读 Adam Geitgey 的 文章 。
每个卷积层将使用 ELU 作为激活函数。ELU已被证明是卷积层的较好 激活函数。
我们设定一个具有ELU激活函数的完全连接层和一个输出层(具有线性激活函数的完全连接层),其输出为每个动作的Q值估计。
经验回放:更有效地利用观察到的体验
经验回放将帮助我们处理两件事:
避免忘记以前的经历。
减少经验之间的相关性。
我将解释这两个概念。
这部分和插图的灵感来自Udacity的Deep Learning Foundations Nanodegree的Deep Q Learning章节中的重要解释 。
避免忘记以前的经历
我们有一个很大的问题:权重的可变性,因为行动和状态之间存在高度相关性。
请记住在第一篇文章(强化学习简介)中,我们谈到了强化学习过程:
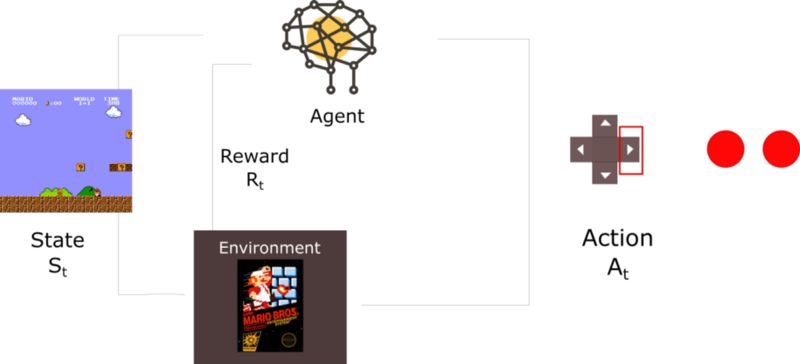
在每个时间步,得到一个元组(state, action, reward, new_state)。从(这个元组)中学习,然后扔掉这个经验。
版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/25314.html


